Gemini CLI Reverse Engineering
Disclaimer: I created this article from the open-source code on GitHub. Although I work at Google, I am not part of the Gemini CLI team and have not been in touch with them.
Table of Contents
- The Main Logic Flow
- The Prompts
- The Tests
- The Memory
- The UI
- The Agent Library
- The Tools
- The Telemetry
- Conclusion
- Afterword: The Search
I was curious how gemini-cli was written, after all it worked quite well and was as close to Cursor as Google had gotten. With its awkward vim feeling, it was the first step of Gemini in the agent paradigm, where the LLM is augmented to interact with your computer through the command line.
On the product side, I think many like me were too lazy to leave IntelliJ for a VSCode-like editor like Cursor so they were mainly surfing the AI wave through IntelliJ plugins (eg: Gemini Code Assist), copy-pasting to online LLMs chat interace or had built their own custom solutions. gemini-cli came as a step up in the AI coding experience for those people.
I need to say though, comparing Cursor to gemini-cli is where I understood the importance of the ‘product’ side in AI. Both engines have the same level of performance and intelligence, but Cursor has already solved all the little things that can be annoying when coding with AI: applying changes, switching LLMs, tracking context length, scanning a directory… All those little frictions that show the limitations of human-agents interactions have been solved already with opinionated takes on features, which makes the experience so much smoother. That’s the value in paying for Cursor.
But onto gemini-cli, a very open-ended agent that allows you to build anything, but sometimes goes down the rabbit hole. Is it something you could have built yourself easily ? Let’s dig into it.
The Main Logic Flow
As often said, an agent is just an LLM in a for loop with break conditions - and here is no different.
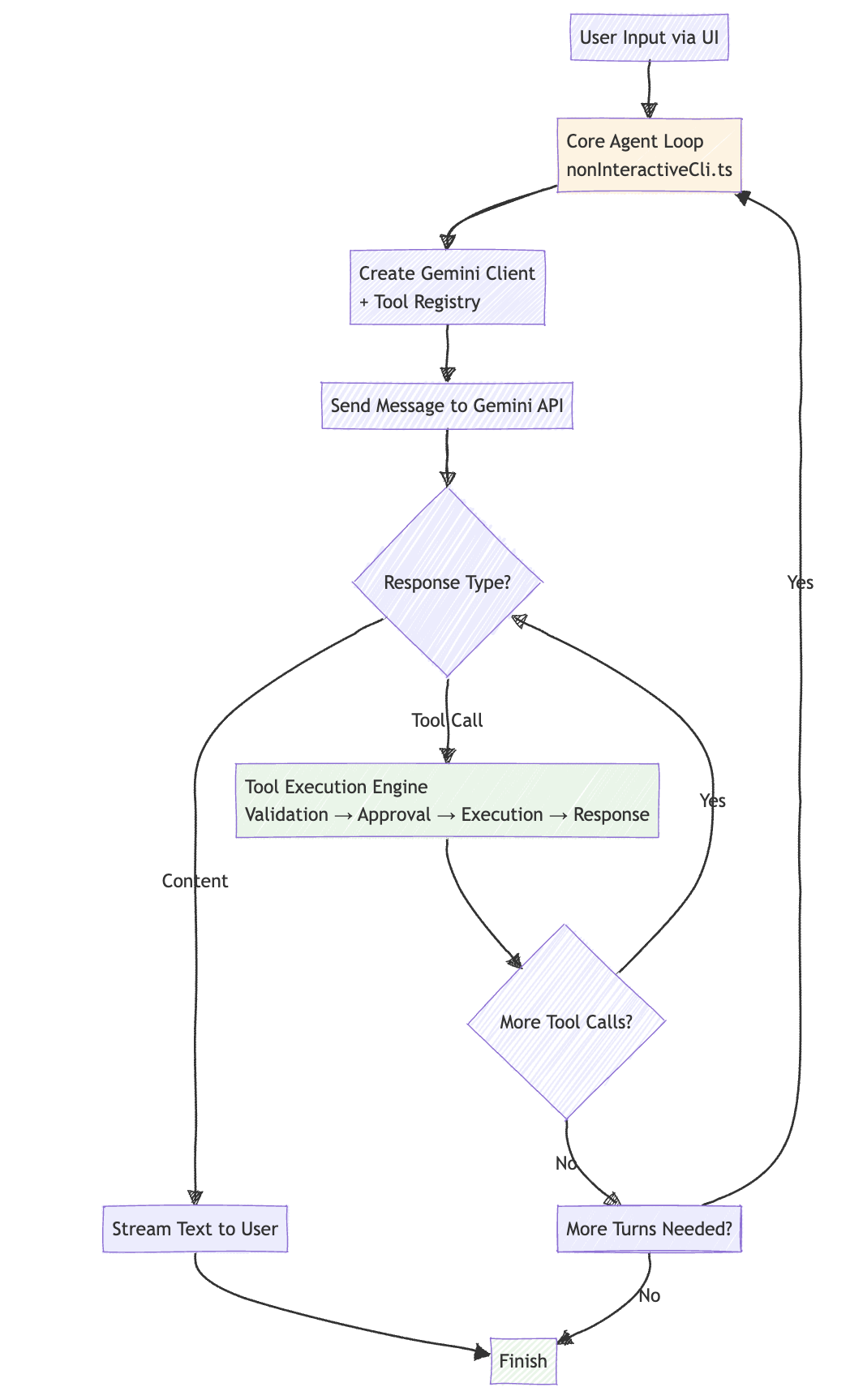
How does gemini-cli decide no more turns are needed? It doesn’t. The decision is made by Gemini itself through a simple mechanism: tool calls.
Here’s the exact flow: Gemini responds to the user’s request. If that response contains any tool calls, all tools are executed and their results are sent back to Gemini for the next turn. If this 2nd response contains no tool calls, the turn ends.
This means complex tasks like “build a piece of code” can span multiple turns (each turn: Gemini decides what tools to use → tools execute → results go back to Gemini), while simple requests end as soon as Gemini has enough information to respond without needing tools.
There are safety nets - turn limits, infinite loop detection, and user cancellation - but the core decision is left to the AI’s judgment of whether it needs more tools to complete the task.
The Prompts
There are only 2 and both located at packages/core/src/core/prompts.ts
We start by them because this ‘natural language’ (NL) code is more important than programming code itself, which machines have widely automated, while NL code speaks more directly of the intent and design decisions of the programmers.
The Core System Prompt
This one is 20 page long - yes hard to believe - and defines the agent’s behavior 360 degrees. I compiled some of the most clear cut instructions below:
- Core Mandates: Guidelines for code conventions, libraries/frameworks usage, style & structure, comments, proactiveness.
Mimic the style (formatting, naming), structure, framework choices, typing, and architectural patterns of existing code
NEVER assume a library/framework is available or appropriate
*NEVER* talk to the user or describe your changes through comments
- Operational Guidelines: Tone and style for CLI interaction, security rules, tool usage guidelines
Use 'grep' and 'glob' search tools extensively to understand file structures, existing code patterns, and conventions
Always apply security best practices. Never introduce code that exposes, logs, or commits secrets, API keys, or other sensitive information
Use the 'memory' tool to remember specific, *user-related* facts or preferences when the user explicitly asks
Execute multiple independent tool calls in parallel when feasible
It is funny to see many of the inner logic we would have hardcoded in a traditional software is here exposed to the agent as concepts it should use - but won’t necessarily to so when the opportunity comes.
-
Environment-specific instructions: Different prompts for sandbox vs non-sandbox environments. Here a different prompt is appended depending on the user environment. Any user-related memory is added.
-
Git repository handling: Special instructions when working in git repositories
When asked to commit changes or prepare a commit, always start by gathering information using shell commands
Prefer commit messages that are clear, concise, and focused more on 'why' and less on 'what'
There were also some few-shot examples provided like:
user: list files here. → [tool_call: ls for path '/path/to/project']
Surprisingly, there were many instructions that seemed too vague to be useful for the LLM and probably cluttered the context like:
Think about the user's request and the relevant codebase context
The Compression Prompt
Managing context is key to effective agents and so a strategy is employed here to keep it short.
The prompts asks for summarizing conversation history into structured XML format with sections like:
<overall_goal><key_knowledge><file_system_state><recent_actions><current_plan>-> a todo list of [DONE], [IN PROGRESS], [TODO] actions that agents often use
Here is an extract that is quite self-explanatory:
When the conversation history grows too large, you will be invoked to distill the entire history into a concise, structured XML snapshot.
This snapshot is CRITICAL, as it will become the agent's *only* memory of the past.
First, you will think through the entire history in a private <scratchpad>.
Review the user's overall goal, the agent's actions, tool outputs, file modifications, and any unresolved questions.
Identify every piece of information that is essential for future actions.
After your reasoning is complete, generate the final <state_snapshot> XML object.
Be incredibly dense with information. Omit any irrelevant conversational filler.
This compression is triggered when the conversation history approaches 70% of the model’s token limit . The exact conditions are:
- Token Threshold:
COMPRESSION_TOKEN_THRESHOLD = 0.7(70%) - Preserve Threshold:
COMPRESSION_PRESERVE_THRESHOLD = 0.3(30% of recent history is preserved) - Trigger Point: Called automatically at the start of each new turn in
sendMessageStream() - Force Option: Can be manually triggered with
/compresscommand
The system compresses the oldest 70% of the conversation history into the structured XML format, while preserving the most recent 30% as-is.
The Tests
How do you even test such an agent end2end ? The latent space of possibilities is infinite.
Located at /integration-tests/, it seems only basic single-turn single-action operations are tested through NL prompts.
Each test has 1 prompt and 1 verification.
file-system.test.js&write_file.test.js
edit test.txt to have a hello world message → verifies file is modified
show me an example of using the write tool. put a dad joke in dad.txt → verifies file creation
google_web_search.test.js
what planet do we live on → verifies response contains “earth”
I guess this ensures tests are less flaky, run fast and easier to debug - but it is not the real deal I expected.
There is alsp a TestRig helper class which creates isolated working directories for each test.
The other 200+ tests files are unit tests that check individual components in isolation like the UI.
The Memory
gemini-cli will remember what you explicitly ask it to remember by writing the information to ~/.gemini/GEMINI.md using the MemoryTool class

Then if I open GEMINI.md, I can see the new information that got written there.

Here is a Mermaid diagram explaining how memory logic happens. It is very simple. Just a tool call.
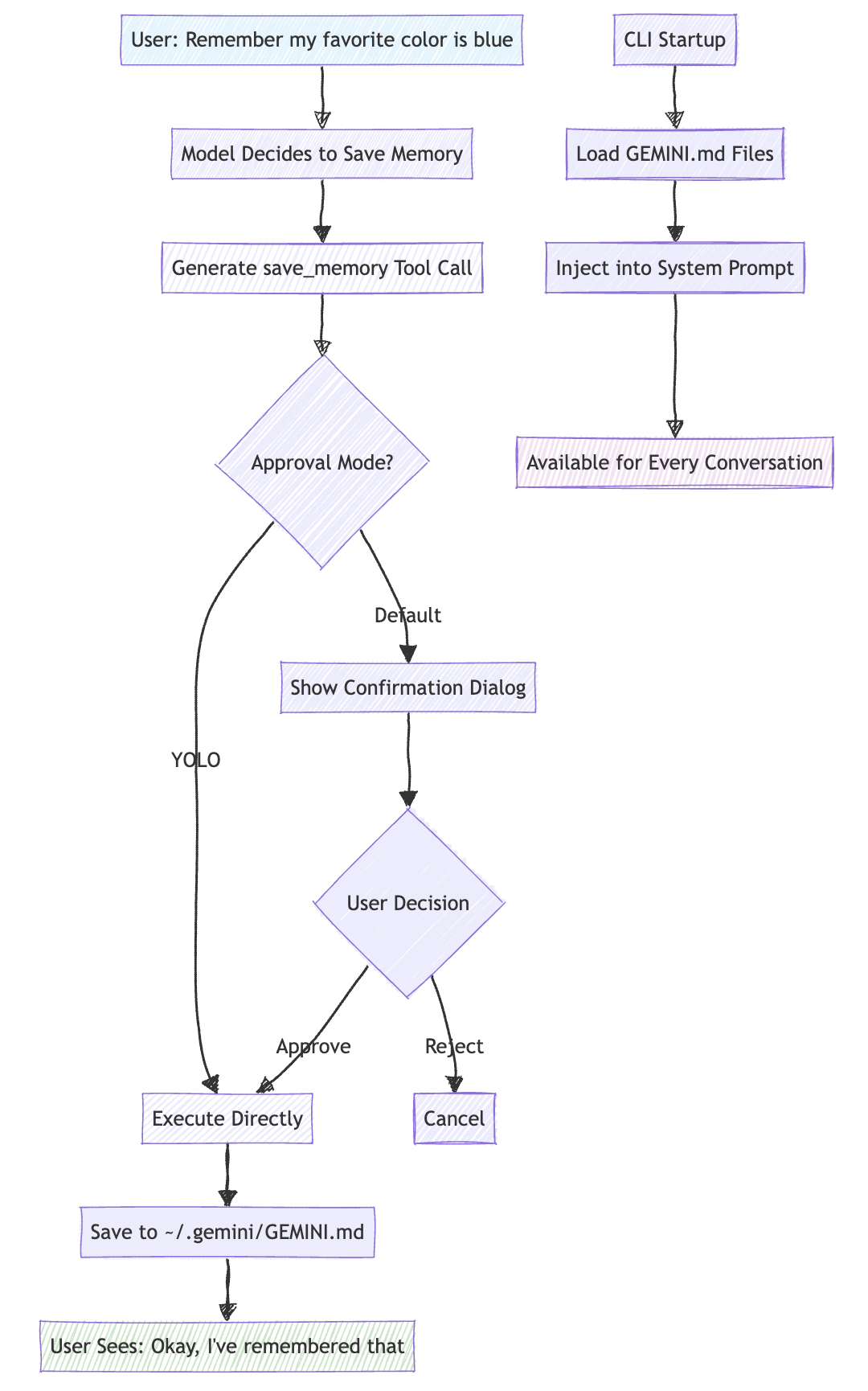
Memory Flow Summary:
- Save: User request → Model decision → Tool execution → File persistence
- Load: CLI startup → File discovery → System prompt injection → Available everywhere
The most important validation happens at the model level through the tool description where the AI model decides if it’s worth remembering that information, see below.
’’’ const memoryToolDescription = Use this tool:
- When the user explicitly asks you to remember something (e.g., “Remember that I like pineapple on pizza”, “Please save this: my cat’s name is Whiskers”).
- When the user states a clear, concise fact about themselves, their preferences, or their environment that seems important for you to retain for future interactions to provide a more personalized and effective assistance.
Do NOT use this tool:
- To remember conversational context that is only relevant for the current session.
- To save long, complex, or rambling pieces of text. The fact should be relatively short and to the point.
- If you are unsure whether the information is a fact worth remembering long-term. If in doubt, you can ask the user, “Should I remember that for you?” ‘’’
So yes, to sum up, the memory strategy is intentionally minimalist:
- Explicit & Not Automatic Learning: Only save what users explicitly ask to remember
- Compressed History: Dense summaries of recent conversations
The UI
The UI is built with React + Ink, a library that renders React components to the terminal. This is quite clever as it allows the team to use familiar React patterns while building a terminal interface. On the product level, it was also clever, nobody expected the next agent UI to live in your terminal.
If you were wondering why Type TypeScript over Python for an AI agent, the answer is here: TypeScript/Node.js has superior terminal UI libraries. Python’s terminal UI options like Rich and Textual are more limited.
The main component in the UI is App.tsx which orchestrates everything:
’'’typescript // The React components inside App
’’’

The vim feeling comes from the useVim hook that implements full vim keybindings.
Oh and the beautiful Gemini at the top is ASCII art that you can generate and switch for your own name if you would like.
Use a generator like https://ascii.co.uk/text with font style “ANSI Shadow” and copy paste to gemini-cli/dist/src/ui/components/AsciiArt.js (type which gemini to find where and use nano to edit).
The Agent Library
You might be wondering if they used any of the popular agent frameworks like LangChain. The answer is no - they built everything from scratch.
Looking at the package.json files, there are no traces of the usual suspects. No LangChain, no LangGraph, no AutoGen, no CrewAI. Instead, they went with a custom approach using Google’s official SDK:
’'’json “@google/genai”: “1.9.0” ‘’’
They probably wanted full control over the agent flow rather than being constrained by existing frameworks.
The result is a custom agent system with:
- Custom Tool Registry:
packages/core/src/tools/tool-registry.ts - Custom Turn Management:
packages/core/src/core/turn.ts - Custom Memory System:
packages/core/src/tools/memoryTool.ts - Custom Prompt Management:
packages/core/src/core/prompts.ts
They also used the Model Context Protocol (MCP) for tool integration: ‘'’json “@modelcontextprotocol/sdk”: “^1.11.0” ‘’’
So while the rest of us are building agents with LangChain or LangGraph, they went ahead and built their own sophisticated agent framework. It’s a reminder that when you have the resources and need full control, building from scratch is the way to go. I have seen some startups echoing this mentality as well.
The Tools
gemini-cli comes with 11 built-in tools that cover the essential operations you’d need for development work. They’re all registered in the ToolRegistry and can be enabled/disabled through configuration. The tool system is extensible as any MCP-compatible server can be added. The agent will then decide automatically when to use them based on their description.
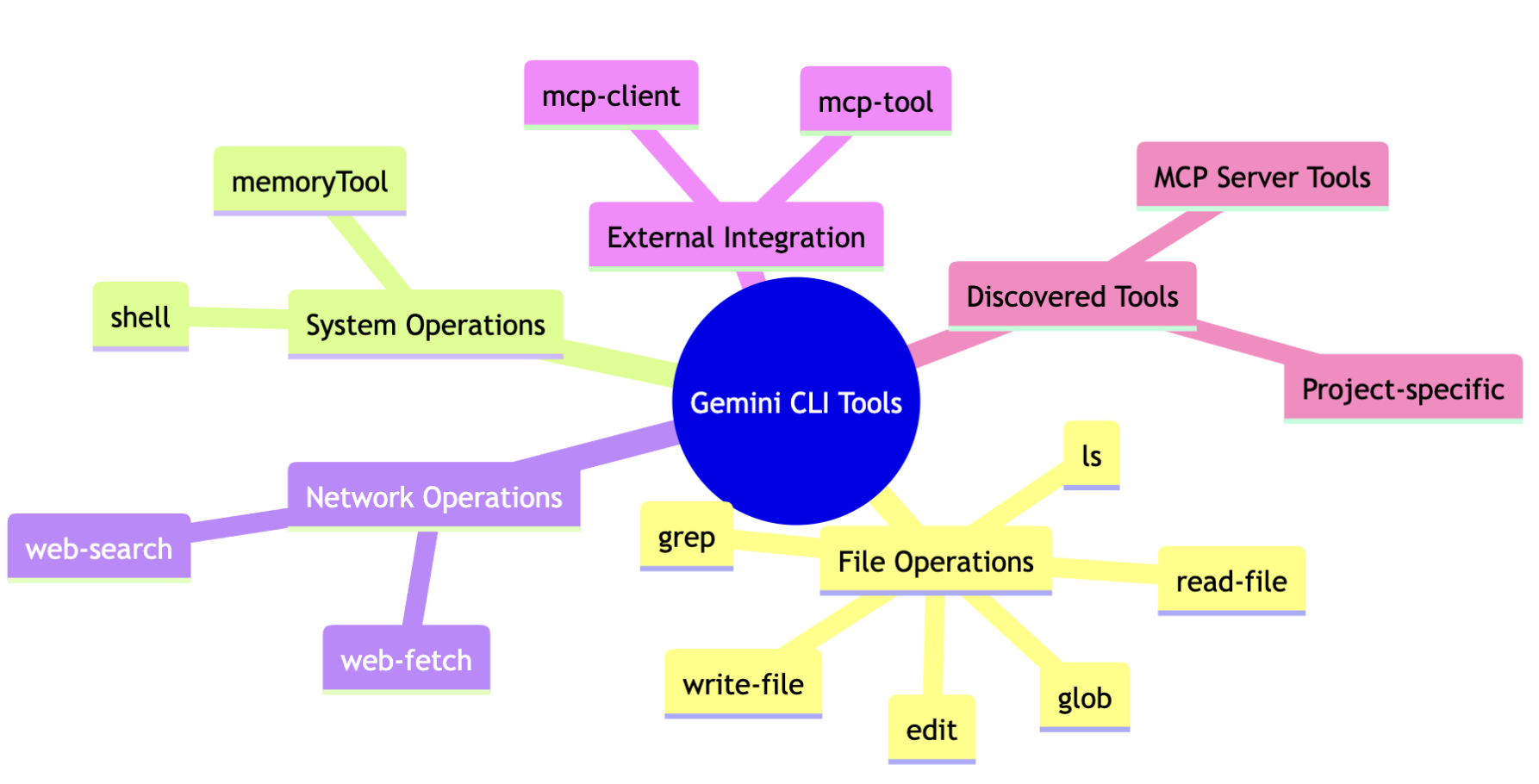
File System Tools
ls- List files and directoriesread_file- Read a single file’s contentsread_many_files- Read multiple files at oncewrite_file- Create new filesedit- Edit existing files with AI assistancegrep- Search for text patterns in filesglob- Find files using glob patterns
System Tools
shell- Execute shell commandsweb_fetch- Make HTTP requests to web APIsweb_search- Search the web using Google Search
Memory Tools
save_memory- Save information to persistent memory (~/.gemini/GEMINI.md)
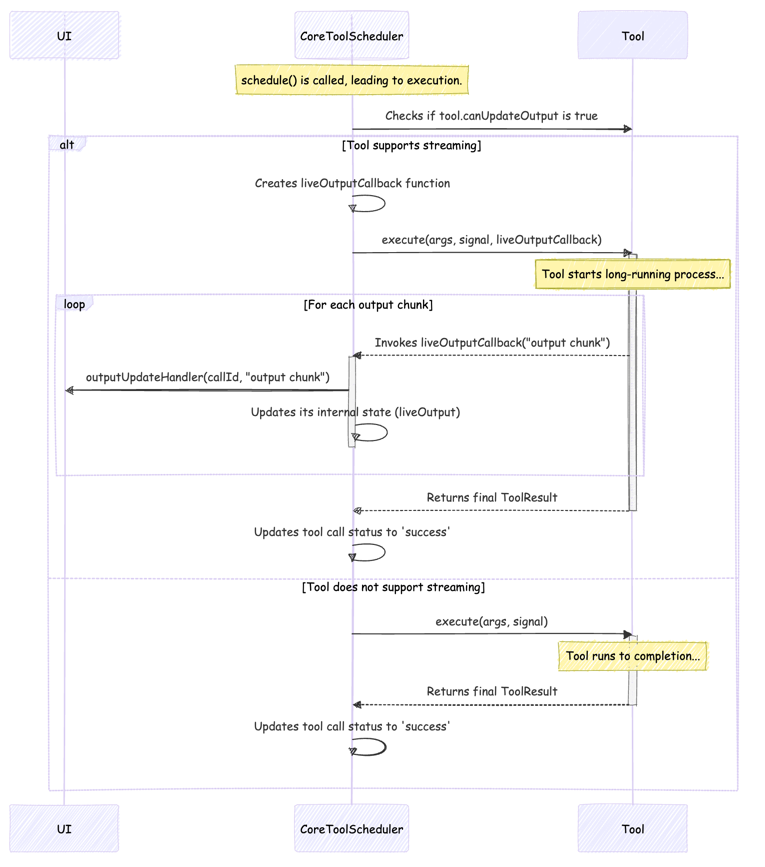
Once the model decides to use a tool, here is how the execution works, nothing fancy:
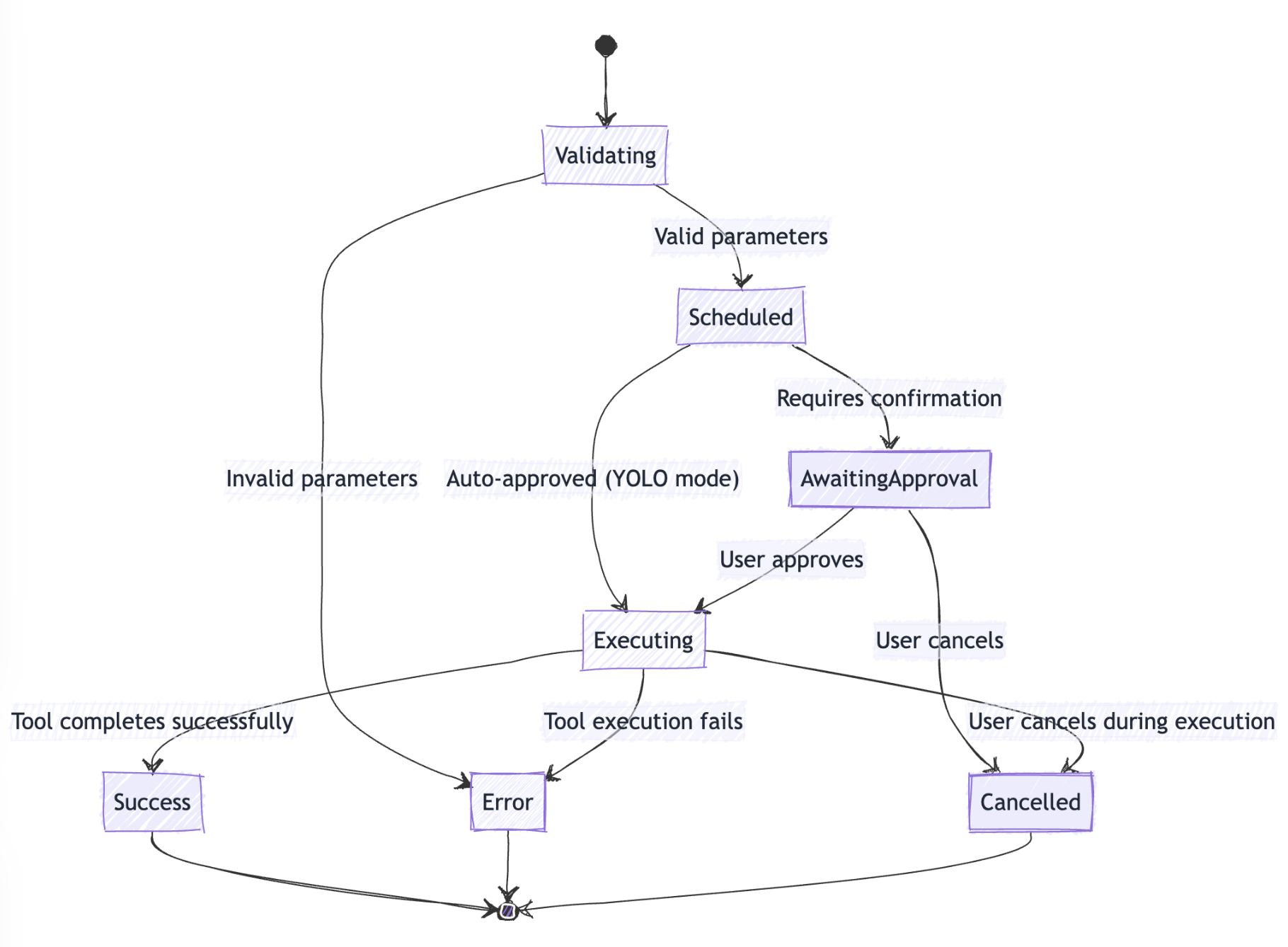
For long running tools, a classic callback pattern is used. The scheduler provides a function to the tool, and the tool calls that function with its output whenever it has something new to report, creating a direct stream from the executing tool back to the UI.
The Telemetry
Should You Be Worried ? No, not really. Telemetry is disabled by default - you have to explicitly opt-in to any data collection. Even when enabled, the system uses three separate settings: general telemetry (for debugging), usage statistics (for Google analytics), and prompt logging (for user messages). You can enable/disable each independently.
What gets collected (if enabled): Configuration settings (which model you use, which tools are enabled), tool execution data (which tools you call, how long they take, success/failure), API interaction metrics (response times, token usage), and optionally your actual prompts.
What doesn’t get collected: Your file contents, API keys, secrets.
Conclusion
So much code - 500 files, 100k lines - and many concepts that come together but that stay relatively simple when taken apart.
I have this bittersweet feeling we robbed the magic out of gemini-cli!
Afterword: The Search
…Or how Gemini CLI tames giant monorepos - without melting your tokens.
I added this part after a colleague, Matt, rightly pointed this article was missing “the real secret sauce […] any tricks it pulls to help index large monorepos”.
The Indexing
Think of Gemini CLI like a neat roommate in a chaotic, warehouse-sized code loft. It doesn’t pre-index the whole warehouse; instead, it keeps a fast, opinionated map and grabs the right boxes only when you ask, and it packs them into Gemini’s context like a Tetris grandmaster.
- Multi‑root brain: It treats your repo(s) as a set of “workspace directories,” so searches, ls, grep, glob all work across multiple roots while enforcing strict “stay‑inside” boundaries. It resolves real paths to avoid symlink shenanigans.
- Ignore stack: Anything in the
.gitignoreand .geminiignorewill be ignored. The CLI will also tell you how many files it refused at the door. Btw, a.geminiignoreis a gitignore‑style project file that reminds Gemini CLI which paths to skip. One is added at the root of each workspace directory you’ve added. - Git‑first searching: It prefers git grep (fast, indexed), then system grep, then a JS glob+stream fallback. That means it returns only the lines you need, not the entire warehouse.
- Glob that feels fresh: File finding is recency‑aware so recently modified stuff floats to the top.
- Parallel BFS: When it must scan folders, it does it breadth‑first in parallel batches, so you see results faster in big trees. It stops when a maxDirs cap is reached and tracks visited paths to avoid loops.
- Smart @‑completion and @‑reading: Typing @file or @dir/** autocompletes, respects ignore rules, and only reads what you asked, not “the entire frontend since 2017.” Also hides dotfiles by default.
The Context
Now the calorie math: Getting your code into the model without blowing the context budget.
- Startup diet: It sends a compact folder tree of each workspace directory, capped at 200 items. That’s “shape of repo,” not “contents of repo.”
- Full‑context is opt‑in: You can ask it to slurp more, but only if you flip a flag. Even then, heavy guardrails kick in.
- Per‑file portion control: Text reads cap at 20MB, first 2,000 lines, and 2,000 characters per line—clearly marked with “[truncated]” hints. Images/PDFs are only included if explicitly requested by names or extension, and go as inlineData (base64 + mime), not plaintext dumps.
- Tool output gets summarized: Noisy shell output can be auto‑summarized down to a token budget before it ever hits the prompt.
- History compresses itself: As seen in The Compression Prompt
Practical Example
Let’s say you type:
How does the cache work in @packages/core/src/utils/*.ts? Also check @grep.ts and @glob.ts
What Gemini CLI does under the hood:
- Parse @… parts, resolve paths/globs across all workspace dirs, and respect ignore rules. If a piece isn’t a file, it expands to a glob like dir/**.
- Read each referenced file with the limits mentioned above.
- Stitch that content into your prompt as structured parts:
1 │ --- Content from referenced files ---
2 │ Content from @packages/core/src/tools/grep.ts:
3 │
4 │ [File content truncated: showing lines 1-2000 of 2345 total lines. Use offset/limit parameters to view more.]
5 │ export class GrepTool extends BaseTool<...> {
6 │ ...
7 │ }
8 │
9 │ Content from @packages/core/src/tools/glob.ts:
10 │ export class GlobTool extends BaseTool<...> {
11 │ ...
12 │ }
13 │ --- End of content ---
- If the combined prompt is getting chunky, tools like shell output get summarized first; if the whole chat approaches the window, the oldest chunk is compressed into a dense
and the freshest 30% remains verbatim.
In Short
So in the end we have:
- Indexing tricks: multi‑root, ignore stack, git‑first grep, recency‑glob, parallel BFS, bounds/symlink safety.
- Context tricks: folder map, per‑file caps, summarization, automatic compression.
- And a huge mermaid diagram to sum it up
{kind=link}